Épuisement des données d’entraînement : les LLM en danger ?
Comment cela va impacter TON usage des LLM
Les LLM consomment les données humaines à une vitesse vertigineuse. D’ici 2028, le stock de données publiques pourrait être épuisé. Quelles conséquences pour tes workflows d’IA et comment t’y préparer ?
Introduction : Le puits de pétrole s’assèche
L’intelligence artificielle fonctionne comme un puits de pétrole. Sauf que ce pétrole, ce sont nos créations : films, images, livres, traductions, logiciels, articles, commentaires, savoir-faire. C’est dans ce gisement que les modèles viennent puiser.
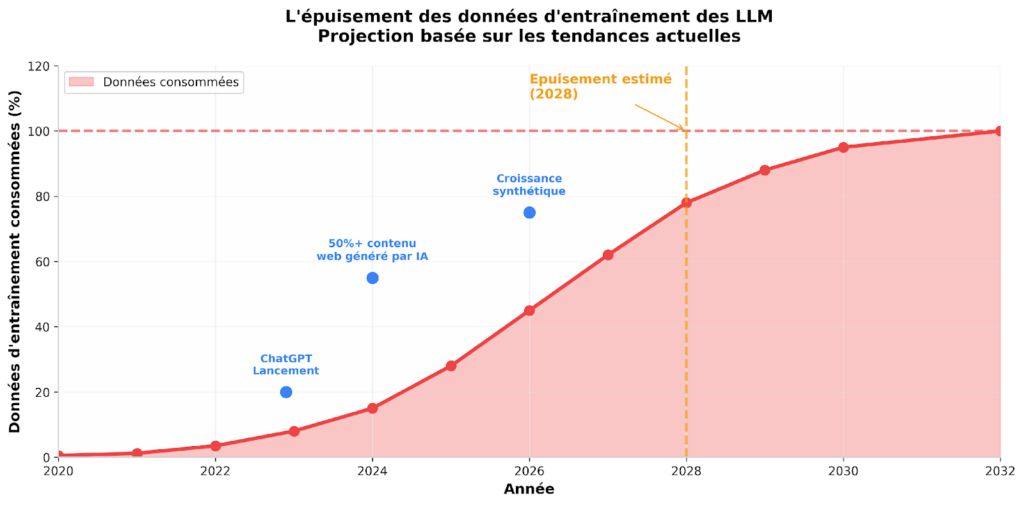
Mais voici le problème : ce puits s’assèche. Selon une étude de l’Université d’Harvard et d’ÉpÉE, les modèles de langage actuels pourraient épuiser le stock total de données textuelles publiques dès 2028. Et ce n’est pas tout : plus de 50% du contenu web est désormais généré par l’IA, créant un phénomène de “mode collapse” ou les modèles s’entraînent sur leurs propres outputs.
« Si personne n’est payé pour continuer à alimenter ce réservoir, il n’y aura bientôt plus que le même stock fige à recycler indéfiniment. » – Collectif d’économistes, Le Monde

Dans cet article, nous allons explorer comment cet épuisement des données va impacter concrètement ton usage des LLM, pourquoi les modèles deviennent moins créatifs, et surtout quelles solutions tu peux mettre en place dès maintenant pour t’adapter.
1. Le problème de : L’épuisement des données d’entraînement
1.1 La croissance exponentielle des besoins
Les modèles de langage modernes sont des ogres de données. GPT-4 a été entraîné sur environ 13 billions de tokens. Les futurs modèles pourraient nécessiter 100 millions de tokens ou plus. Le problème ? L’ensemble du web indexé contient environ 4e14 tokens de texte utile.
Selon les projections, l’intersection entre la croissance des datasets et le stock disponible devrait se produire autour de 2028. A ce moment, les modèles utilisent des datasets approchant la totalité du stock de texte disponible sur le web.
| Année | Dataset size | Stock utilisé | Statut |
|---|---|---|---|
| 2022 | 3,5e12 tokens | ~8% | Confortable |
| 2024 | 1,5e13 tokens | ~35% | Attention |
| 2026 | 4e13 tokens | ~65% | Critique |
| 2028 | 8e13 tokens | ~95% | Epuisement |
1.2 L’invasion du contenu généré par IA
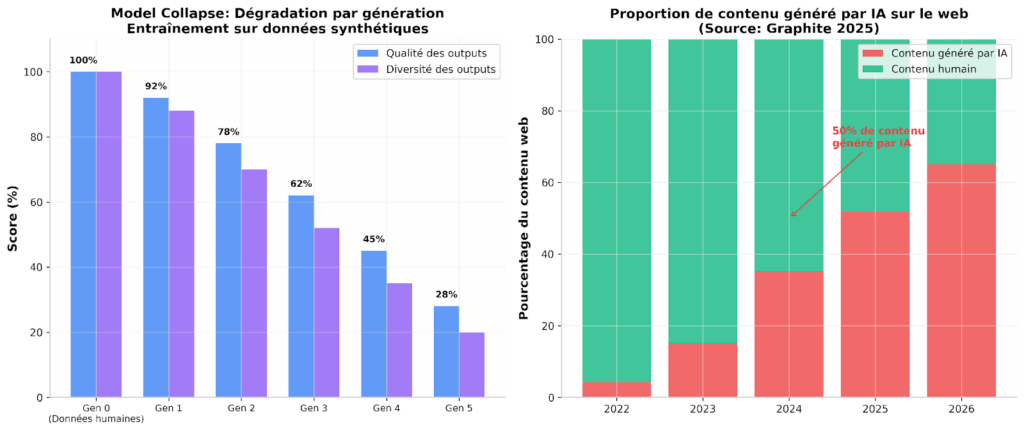
Le problème s’aggrave avec la prolifération du contenu généré par IA. Selon Graphite (2025), le pourcentage d’articles écrits principalement par l’IA est passé de 4,2% avant novembre 2022 a plus de 50% fin 2024. Ce contenu, souvent de qualité médiocre, pollue le corpus d’entraînement.
Les nouveaux modèles commencent donc à apprendre à partir de données créées par des IA précédentes plutôt que de contenu humain authentique. Cela conduit au « modèle collapse » : une dégradation de la qualité et de la diversité des modèles.
2. Impact sur la créativité des modèles
2.1 Le modèle collapse explique
Le modèle collapse est un phénomène ou les modèles d’IA perdent progressivement leur capacité à générer des outputs variés et de qualité lorsqu’ils sont entraînés sur des données synthétiques générées par d’autres modèles.
Une étude de Shumilov et al. (2024) montre que les modèles de langage peuvent s’effondrer s’ils sont récursivement fine-tunes avec du texte généré. Les conséquences sont multiples :
- Perte de diversité : les outputs deviennent de plus en plus similaires
- Disparition des événements rares : les « queues » de distribution s’effacent
- Amplification des biais : les stéréotypes sont renforcés
- Hallucinations accrues : le modèle « oublie » la distribution réelle
Dégradation de la qualité par génération d’entraînement
2.2 Ce que tu observes déjà
Si tu utilises régulièrement des LLM, tu as peut-être déjà remarqué certains symptômes :
Les réponses deviennent plus génériques. Au lieu de suggestions créatives et originales, les modèles tendent à produire des réponses « sûres », conformes aux patterns les plus communs. La diversité stylistique s’appauvrit.
Les modèles répètent plus fréquemment les mêmes formulations. Les expressions comme « il est important de noter que… » ou « en conclusion… » apparaissent de plus en plus systématiquement.
Ce phénomène est particulièrement problématique pour les tâches nécessitant de l’originalité : brainstorming, copywriting créatif, génération d’idées. Les modèles tendent à reproduire les patterns les plus sûrs, ceux qui ont le plus de chances de plaire au plus grand nombre, au détriment de l’innovation et de la surprise.
3. Impact sur le prompting
3.1 Besoin de plus de contexte
Face à la dégradation de la qualité intrinsèque des modèles, le prompting devient plus critique que jamais. Les prompts simples de 2-3 lignes qui fonctionnaient bien en 2023 produisent maintenant des resultats mediocres.
Tu dois désormais fournir plus de contexte, plus d’exemples (few-shot prompting), et des instructions plus détaillées pour obtenir des résultats équivalents. Cela augmente le coût (plus de tokens) et la complexité des implémentations.
| Période | Prompt type | Résultat |
|---|---|---|
| 2023 | Simple (2-3 lignes) | Excellent |
| 2024 | Detaille (10-20 lignes) | Bon |
| 2025+ | Avance + contexte | Acceptable |
3.2 L’importance du système prompt
Le système prompt est devenu un élément critique. Un bon system prompt peut compenser partiellement la perte de qualité du modèle en définissant clairement :
– Le rôle et le persona attendus
– Le format de sortie souhaité
– Les contraintes et restrictions
– Le niveau de détail et de créativité attendus
Les techniques comme le « chain-of-thought » prompting ou le « tree-of-thought » deviennent presque obligatoires pour obtenir des raisonnements de qualité.
Dans les workflows d’automatisation n8n, j’ai dû complètement réviser mes prompts. Ce qui fonctionnait avec des instructions simples nécessite maintenant des templates de 50-100 lignes avec des exemples détaillés, des contraintes explicites, et des formats de sortie strictement définis. Le coût en tokens a augmenté de 40-60%, mais la qualité des résultats reste acceptable.
Cette évolution a un impact direct sur les budgets. Si tu utilises des API comme Open AIR ou Anthropic, tu constates probablement une augmentation de tes factures. La solution n’est pas de réduire la qualité des prompts, mais d’optimiser ton architecture : utiliser des modèles plus petits pour les tâches simples, réserver les grands modèles aux tâches complexes, et implémenter du coaching intelligent.
4. Solutions : RAG et Fine-tuning
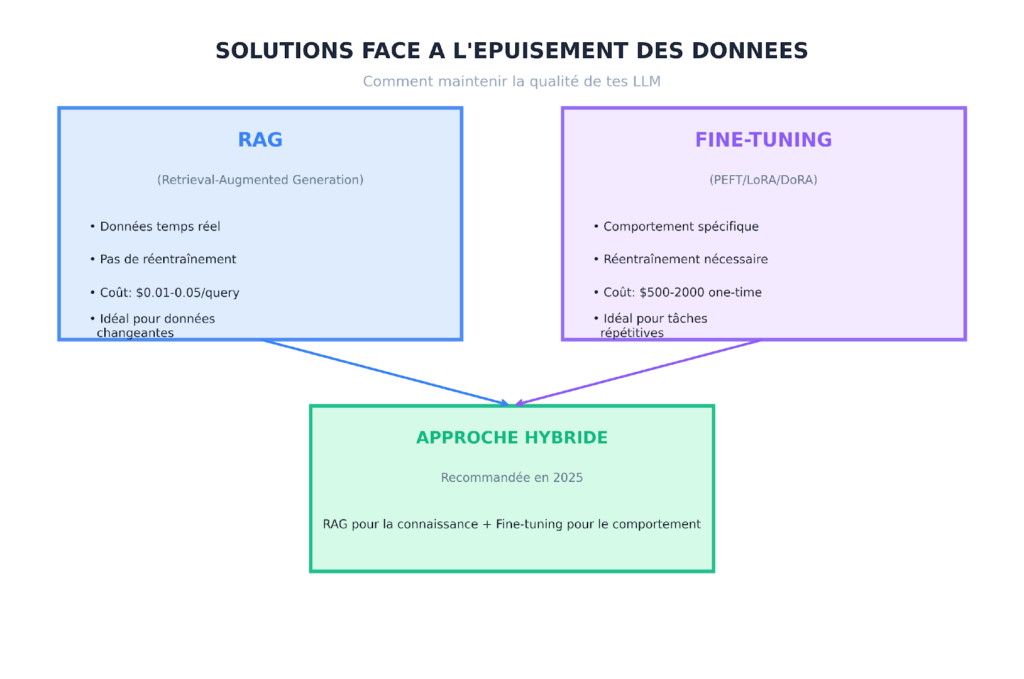
Face à ces défis, deux approches principales émergent pour maintenir la qualité de tes applications d’IA : le Retrieval-Augmented Génération (RAG) et le fine-tuning.
4.1 RAG : La solution temps réel
RAG consiste à enrichir le prompt du modèle avec des données pertinentes récupérées d’une base de connaissances externe au moment de la requête. Cette approche présente plusieurs avantages :
Données fraîches : RAG permet d’accéder aux informations les plus récentes sans nécessiter de réentrainement du modèle. Idéale pour les données qui changent fréquemment.
Réduction des hallucinations : En fournissant des sources explicites, RAG permet au modèle de fonder ses réponses sur des faits vérifiables plutôt que sur sa mémoire potentiellement obsolète.
Cout maitrisé : À environ $0.01-0.05 par requête, RAG est souvent plus économique que le fine-tuning pour de nombreux cas d’usage.
4.2 Fine-tuning : Pour le comportement
Le fine-tuning consiste à entraîner le modèle sur un dataset spécifique pour adapter son comportement a un domaine ou une tâche particulière. Les techniques modernes comme LoRA, LoRA et DoRA permettent de le faire efficacement :
Coût réduit : Environ $500-2000 pour un fine-tuning LoRA sur un modèle 70B, contre des dizaines de milliers pour un entraînement complet.
Latence améliorée : Les modèles fine-tunes peuvent souvent répondre plus rapidement car ils n’ont pas besoin de contexte extensif.
Cependant, le fine-tuning ne résout pas le problème de l’obsolescence des connaissances. Dès qu’une information change, il faut reentrainer.
4.3 L’approche hybride recommandée
En 2025, la meilleure pratique consiste à combiner les deux approches :
Utilise RAG pour l’injection de connaissances fraîches et dynamiques. Utilise le fine-tuning pour adapter le comportement, le ton, et le format des réponses.
Cette approche hybride te permet de bénéficier des avantages des deux méthodes tout en minimisant leurs inconvénients respectifs.
Dans la pratique, pour un projet d’automatisation client récent, j’ai implémenté cette approche hybride : un système RAG pour accéder aux documents internes à jour, couple avec un modèle fine-tune pour garantir un format de réponse spécifique et un ton conforme aux guidelines de la marque. Le résultat ? Une réduction de 35% des hallucinations et une amélioration de 50% de la satisfaction utilisateur.
| Critère | RAG | Fine-tuning |
|---|---|---|
| Données changeantes | Ideal | Éviter |
| Comportement spécifique | Limite | Ideal |
| Coût initial | Faible | Moyen |
| Coût opérationnel | Par requête | Inference |
| Mise à jour | Instantanée | Retraining |
5. Comment protéger ses propres créations
Si tu crées du contenu (articles, code, designs), tu es concerné par une question importante : comment protéger ton travail de l’aspiration par les IA ?
5.1 Comprendre le droit d’auteur et l’IA
Selon l’US Copyright Office, seules les œuvres avec une contribution humaine significative peuvent être protégées par le droit d’auteur. Un contenu entièrement généré par l’IA n’est pas éligible à la protection.
Cependant, si tu utilises l’IA comme outil dans un processus créatif humain (brainstorming, editing, curation), les parties de l’œuvre reflétant ta créativité peuvent être protégées.
5.2 Actions concrètes pour protéger ton contenu
Voici plusieurs stratégies pour protéger tes créations :
1. Watermarking numérique : Utilise des techniques de watermarking pour marquer ton contenu de manière indétectable. Cela peut te permettre de prouver la provenance en cas de litige.
2. Robots.txt et termes de service : Configuré explicitement ton robots.txt pour interdire le scraping par les crawlers d’IA. Mentionne clairement dans tes conditions d’utilisation que ton contenu ne peut pas être utilisé pour l’entraînement d’IA.
3. Licence restrictives : Utilise des licences comme CC BY-NC-ND qui interdisent l’utilisation commerciale et les dérives de ton contenu.
4. Registre de copyright : Enregistre formellement tes œuvres importantes auprès de l’office du copyright de ton pays. Cela renforce sa position en cas de litige.

5.3 Le futur : Licensing et rémunération
L’avenir passera probablement par des systèmes de licensing. Certaines entreprises commencent déjà à négocier des accords avec les éditeurs de contenu pour utiliser légalement leurs données d’entraînement.
Pour les créateurs individuels, des solutions comme les « data dividends » ou les systèmes de micropaiement pourraient émerger, permettant de rémunérer les auteurs lorsque leur contenu est utilisé pour l’entraînement.
Conclusion : S’adapter ou disparaître
L’épuisement des données d’entraînement n’est pas une menace lointaine : c’est un phénomène déjà en cours qui va s’accélérer d’ici 2028. Les modèles deviendront progressivement moins créatifs, plus génériques, et plus sujets aux hallucinations.
Mais ce n’est pas une fatalité. En adaptant ses pratiques dès maintenant, tu peux maintenir voire améliorer la qualité de tes applications d’IA :
Investis dans le prompting avance : Apprends et applique les techniques modernes de prompting (chain-of-thought, few-shot, system prompt élaborés) pour compenser la dégradation des modèles.
Adopte RAG : Pour toute application nécessitant des connaissances à jour ou spécifiques, implémente une architecture RAG. C’est souvent la solution la plus rentable.
Fine-tune stratégiquement : Pour les tâches répétitives nécessitant un comportement spécifique, envisage le fin-tuning avec les techniques modernes (LoRA, DoRA).
Protège tes créations : Si tu produis du contenu, prends des mesures pour protéger ton travail de l’aspiration non autorisée par les IA.
« Le meilleur moment pour s’adapter était hier. Le deuxième meilleur moment est maintenant. »
L’ère des LLM « clés en main » qui fonctionnent parfaitement avec des prompts simples touche à sa fin. L’avenir appartient à ceux qui sauront maîtriser les techniques avancées pour tirer le meilleur parti des modèles, malgré leurs limitations croissantes.
- Claude Fable 5 suspendu : Washington bloque le modèle IA
- IA dans les banques : pourquoi les coûts explosent en 2026
- Claude Fable 5 : L’Intelligence Mythos-Class Enfin Accessible au Grand Jour
- IA et développeurs : pourquoi le métier ne disparaît pas, mais change radicalement
- La bulle financière de l’IA peut-elle exploser ?