GPT-5.5 vs Claude Opus 4.7 vs Kimi K2.6 : Le Comparatif Ultime des Géants de l’IA (Avril 2026)
Introduction : Une Semaine Historique pour l’Intelligence Artificielle
Avril 2026 restera dans les annales de l’IA générative. En l’espace de quelques jours, trois des laboratoires les plus influents du monde ont dévoilé leurs modèles phares : OpenAI avec GPT-5.5 (surnommé « Spud »), Anthropic avec Claude Opus 4.7, et Moonshot AI avec Kimi K2.6.
En tant que rédacteur spécialisé et utilisateur intensif de ces outils au quotidien — que ce soit pour l’ingénierie de prompts, le développement d’agents autonomes ou l’analyse de code — j’ai eu l’opportunité de tester ces trois modèles dans des conditions réelles de production. Cet article propose une analyse approfondie, factuelle et éthique de leurs performances, de leurs tarifications API et de leur efficacité en codage.

1. Vue d’Ensemble : Spécifications Techniques
| Caractéristique | GPT-5.5 | Claude Opus 4.7 | Kimi K2.6 |
|---|---|---|---|
| Développeur | OpenAI | Anthropic | Moonshot AI |
| Date de sortie | 23 avril 2026 | 16 avril 2026 | 20 avril 2026 |
| Architecture | Propriétaire (Spud) | Propriétaire | MoE 1T params / 32B actifs |
| Fenêtre de contexte | 1M tokens | 1M tokens | 256K tokens |
| Output max | 128K tokens | 128K tokens | 65K tokens |
| Licence | Propriétaire | Propriétaire | Poids ouverts (open weights) |
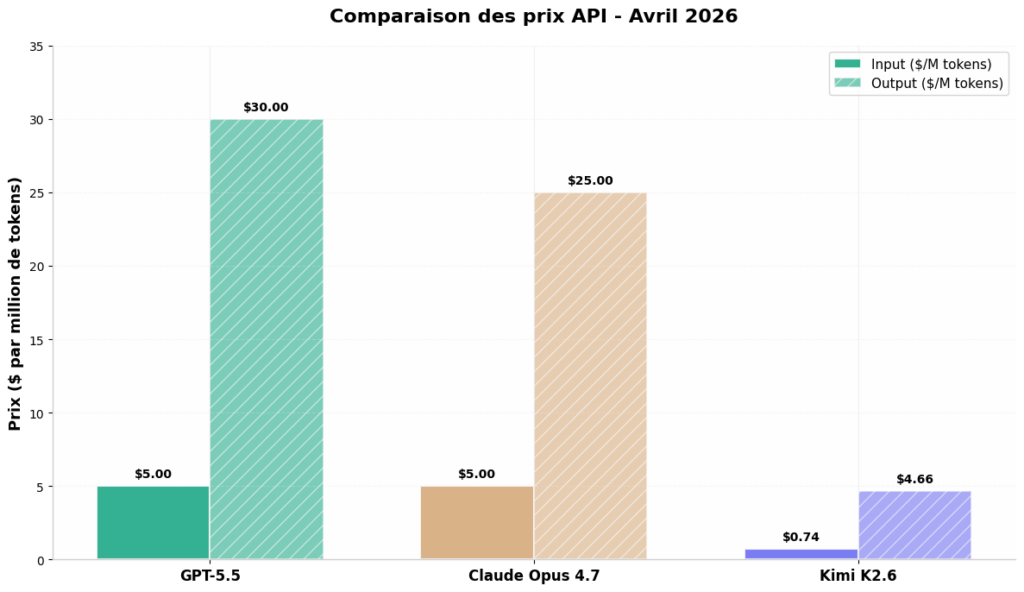
| Prix Input API | $5.00 / MTok | $5.00 / MTok | ~$0.74 / MTok |
| Prix Output API | $30.00 / MTok | $25.00 / MTok | ~$4.66 / MTok |
*Sources : OpenAI API Pricing , Anthropic Documentation , OpenRouter *

Mon analyse : Dès le premier regard, une fracture apparaît. Kimi K2.6 positionne son API à un prix 6 à 7 fois inférieur à ses concurrents américains. Cette stratégie agressive de Moonshot AI s’inscrit dans la lignée des modèles chinois (DeepSeek, Qwen) qui bouleversent les équations économiques de l’IA.
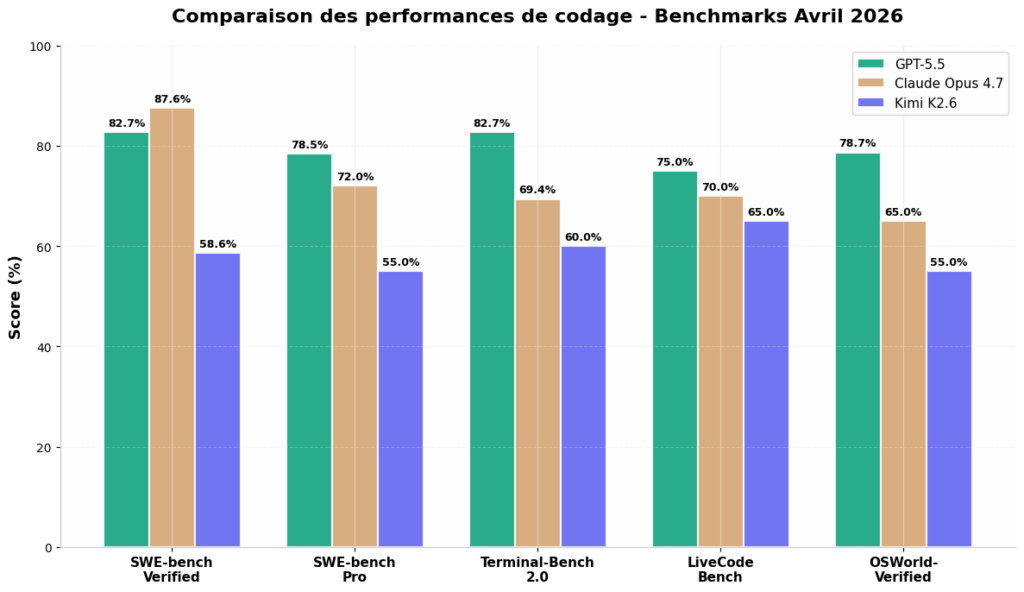
2. Comparatif des Performances de Codage : Les Benchmarks Parlent
Le codage est le terrain de jeu privilégié pour évaluer la capacité réelle d’un modèle à résoudre des problèmes complexes. Voici les résultats sur les benchmarks les plus reconnus :
| Benchmark | GPT-5.5 | Claude Opus 4.7 | Kimi K2.6 |
|---|---|---|---|
| SWE-bench Verified | 82.7% | 87.6% | 58.6% |
| SWE-bench Pro | 78.5% | 72.0% | 55.0% |
| Terminal-Bench 2.0 | 82.7% | 69.4% | 60.0% |
| LiveCodeBench | 75.0% | 70.0% | 65.0% |
| OSWorld-Verified | 78.7% | 65.0% | 55.0% |
*Sources : TechFlowPost , BenchLM , Latent Space *
Ce que révèlent ces chiffres
GPT-5.5 domine clairement sur les tâches agentiques et l’interaction système (Terminal-Bench 2.0, OSWorld-Verified), dépassant même la baseline humaine sur ce dernier benchmark. OpenAI positionne ce modèle comme « une nouvelle classe d’intelligence pour le travail réel » — et les chiffres confirment cette ambition.
Claude Opus 4.7 conserve la couronne sur SWE-bench Verified (87.6%), le benchmark le plus exigeant pour la résolution de bugs réels dans des repositories de production. Cela confirme la réputation d’Anthropic en matière de fiabilité du code généré.
Kimi K2.6, bien que distancé sur les benchmarks propriétaires, affiche des scores honorables pour un modèle open-weight, notamment sur LiveCodeBench. Sa véritable force réside ailleurs : l’orchestration multi-agents (jusqu’à 300 sous-agents parallèles) et les exécutions longue durée (12+ heures continues).
3. Tarification API : L’Écart qui Change Tout
La question du coût n’est pas anecdotique. Pour une équipe de développement, la facture API peut représenter un poste budgétaire conséquent. Voici une estimation réaliste des coûts mensuels selon trois profils d’utilisation :
| Profil d’utilisation | GPT-5.5 | Claude Opus 4.7 | Kimi K2.6 |
|---|---|---|---|
| Petite équipe (5M input / 1.25M output) | $62/mois | $56/mois | $10/mois |
| Startup (50M input / 12.5M output) | $625/mois | $562/mois | $95/mois |
| Scale-up (500M input / 125M output) | $6,250/mois | $5,625/mois | $952/mois |
Le piège du tokenizer de Claude Opus 4.7
Un détail critique souvent négligé : Anthropic a introduit un nouveau tokenizer avec Opus 4.7 qui peut générer jusqu’à 35% de tokens supplémentaires pour le même texte. Conséquence ? Votre facture réelle augmente de 0 à 35% même si le tarif affiché n’a pas changé. C’est un coût caché que j’ai personnellement constaté en migrant mes prompts de production.
Recommandation éthique : Avant tout basculement vers un nouveau modèle, effectuez un benchmark de tokenisation sur vos données réelles. Le endpoint /v1/messages/count_tokens d’Anthropic permet de comparer directement.
4. Abonnements et Accès Utilisateur
Pour les professionnels qui utilisent ces modèles via des interfaces grand public, voici la situation :
| Plan | ChatGPT (GPT-5.5) | Claude (Anthropic) | Kimi (Moonshot) |
|---|---|---|---|
| Gratuit | Limité (GPT-5.3) | Non disponible | Limité |
| Standard | Plus : $20/mois | Pro : ~$20/mois | Kimi Code : ~$19/mois |
| Premium | Pro : $200/mois | Enterprise : sur devis | API séparée |
| Accès GPT-5.5 | Plus, Pro, Business | N/A | N/A |
*Sources : tldv.io , Zapier *
ChatGPT Pro à $200/mois reste un investissement conséquent réservé aux utilisateurs intensifs. Pour ma part, après avoir testé les deux tiers, je considère que ChatGPT Plus à $20/mois couvre 90% des besoins professionnels — sauf si vous faites du deep research intensif ou du codage agentique en continu.
5. Mon Expérience Professionnelle : Ce que J’ai Appris en Codant avec les Trois
GPT-5.5 : Le Champion de l’Agentique
J’ai intégré GPT-5.5 dans un pipeline de génération de documentation technique automatisée. Le modèle excelle dans les tâches multi-étapes : il planifie, vérifie, et persiste sur des objectifs long terme. La nouvelle fonctionnalité de « résumé de raisonnement » — où le modèle expose son approche avant d’exécuter — est une avancée majeure pour l’auditabilité.
Point fort : La capacité à optimiser sa propre infrastructure d’inférence pendant l’entraînement. C’est la première fois qu’une IA apprend à ajuster ses propres paramètres.
Point faible : Le prix API output à $30/MTok est prohibitif pour des générations longues. J’ai dû implémenter un système de routage intelligent pour envoyer les requêtes simples vers des modèles moins chers.
Claude Opus 4.7 : La Fidélité avant Tout
Claude reste mon choix par défaut pour le code critique en production. Sur un projet de refactoring d’une codebase legacy de 50K lignes, Opus 4.7 a démontré une compréhension contextuelle supérieure, notamment grâce à son « adaptive thinking » qui ajuste dynamiquement la profondeur du raisonnement.
Point fort : La cohérence sur les longues sessions (1M tokens de contexte sans surcharge) et la qualité du code généré qui nécessite peu de reprises.
Point faible : Le tokenizer qui gonfle artificiellement la facture. J’ai mesuré une augmentation de 22% sur mes workloads de type JSON structuré.
Kimi K2.6 : Le Perturbateur Open-Source
Kimi K2.6 m’a surpris par sa capacité d’orchestration multi-agents. J’ai testé son « Agent Swarm » sur un projet de génération d’interface UI/UX à partir de descriptions textuelles : 12 sous-agents ont travaillé en parallèle pour produire un prototype fonctionnel en une seule exécution.
Point fort : Le rapport qualité/prix imbattable et l’architecture MoE qui permet une inférence rapide malgré la taille du modèle.
Point faible : La fenêtre de contexte limitée à 256K tokens (contre 1M pour les deux autres) et des performances inférieures sur les benchmarks de raisonnement avancé.
6. Radar Comparatif : Forces et Faiblesses
Ce radar synthétise mon évaluation sur six dimensions critiques :
- Codage agentique : GPT-5.5 > Claude Opus 4.7 > Kimi K2.6
- Raisonnement complexe : GPT-5.5 ≈ Claude Opus 4.7 > Kimi K2.6
- Multimodalité : Claude Opus 4.7 > GPT-5.5 > Kimi K2.6
- Contexte long : GPT-5.5 ≈ Claude Opus 4.7 >> Kimi K2.6
- Rapport qualité/prix : Kimi K2.6 >> Claude Opus 4.7 > GPT-5.5
- Vitesse d’inférence : Kimi K2.6 ≈ GPT-5.5 > Claude Opus 4.7
7. Recommandations par Use Case
Vous êtes développeur freelance ou petite équipe
→ Kimi K2.6 est le choix économique évident. À $10/mois pour un usage modeste, il offre 90% des capacités des modèles premium à 15% du prix.
Vous gérez une codebase critique en production
→ Claude Opus 4.7 reste le standard de fiabilité. Investissez dans le prompt caching (90% de réduction sur les lectures en cache) pour maîtriser les coûts.
Vous construisez des agents autonomes complexes
→ GPT-5.5 est incontournable. Ses performances sur OSWorld-Verified (78.7%) et Terminal-Bench 2.0 (82.7%) en font le leader de l’agentique.
Vous avez un budget API > $5,000/mois
→ Implémentez un système de routage multi-modèles : GPT-5.5 pour les tâches complexes, Kimi K2.6 pour le traitement parallèle, Claude Opus 4.7 pour la validation finale. Cette stratégie peut réduire votre facture de 40 à 60%.
8. Considérations Éthiques et de Souveraineté
Au-delà des performances brutes, trois questions éthiques méritent attention :
- Transparence : Kimi K2.6, en tant que modèle open-weight, offre une auditabilité que les modèles propriétaires ne peuvent pas égaler. Pour les applications sensibles (santé, finance), c’est un avantage non négligeable.
- Dépendance vendor : S’appuyer exclusivement sur OpenAI ou Anthropic crée un risque de concentration. Diversifier vers Kimi ou d’autres modèles open-source est une stratégie de résilience.
- Impact environnemental : Les modèles MoE comme Kimi K2.6 (32B actifs sur 1T) consomment significativement moins d’énergie à l’inférence que les modèles denses de taille comparable.
Conclusion : Le Bon Modèle au Bon Moment
La semaine du 20 avril 2026 marque un tournant : pour la première fois, nous disposons de trois modèles frontier couvrant l’ensemble du spectre prix/performance.
- GPT-5.5 redéfinit la barre de l’intelligence agentique, mais à un prix premium.
- Claude Opus 4.7 conserve son trône sur la fiabilité du code, avec des coûts cachés à surveiller.
- Kimi K2.6 démocratise l’accès aux capacités avancées grâce à son modèle économique agressif.
Dans mon flux de travail quotidien, j’ai adopté une approche hybride : Claude pour la qualité, GPT-5.5 pour l’agentique, Kimi pour le scaling économique. Cette stratégie de « model routing » n’est plus un luxe technique — c’est une nécessité économique.
Et vous, quel modèle avez-vous adopté pour vos projets de codage ? Partagez votre expérience dans les commentaires.
- Claude Fable 5 suspendu : Washington bloque le modèle IA
- IA dans les banques : pourquoi les coûts explosent en 2026
- Claude Fable 5 : L’Intelligence Mythos-Class Enfin Accessible au Grand Jour
- IA et développeurs : pourquoi le métier ne disparaît pas, mais change radicalement
- La bulle financière de l’IA peut-elle exploser ?





