Kimi 2.5 : test, prix et comparaison avec Codex et Claude Code
Analyse comparative avec Codex et Claude Code
Introduction : L’arrivee de KIMI 2.5
Le marché de l’intelligence artificielle générative connaît une accélération sans précédent. Alors que les noms de OpenAI et Anthropic dominaient jusqu’ici les conversations autour des modèles de codage et d’assistance au développement, un nouveau protagoniste émerge avec une force considérable : KIMI 2.5, développé par Moonshot AI. Cette nouvelle itération ne se contente pas d’améliorer incrémentalement son prédécesseur ; elle propose une remise en question fondamentale des équilibres établis, particulièrement dans les domaines du codage assisté par IA et de l’automatisation des workflows de développement.
L’émergence de KIMI 2.5 s’inscrit dans un contexte particulier. Ces dernières années, l’IA générative est passée du statut de curiosité technologique à celui d’outil indispensable pour les développeurs. Les entreprises investissent massivement dans ces technologies, et les choix d’outils ont des conséquences directes sur la productivité, la qualité du code produit, et finalement sur la compétitivité des organisations. Dans ce contexte, chaque avancée technologique significative a le potentiel de redistribuer les cartes du marché.
Pour qui utilise régulièrement ces outils dans un contexte professionnel, l’arrivée de KIMI 2.5 représente bien plus qu’une simple actualité technologique. C’est une opportunité de réévaluer les choix d’outils, d’optimiser les budgets, et surtout d’améliorer significativement la productivité. Cet article propose une analyse approfondie de ce que KIMI 2.5 apporte réellement au marche, en le comparant de manière factuelle a ses principaux concurrents : Codex de OpenAI et Claude Code d’Anthropic.
L’objectif est simple : fournir une analyse basée sur des données vérifiables, des benchmarks reconnus, et un retour d’expérience concret d’utilisation quotidienne. Car au-delà des annonces marketing, ce sont les performances réelles et le rapport qualité-prix qui déterminent l’adoption de ces technologies par les entreprises et les développeurs indépendants.

Il est important de préciser que cette analyse ne prétend pas à l’exhaustivité. Le domaine de l’IA évolue si rapidement que les données d’aujourd’hui peuvent être dépassées demain. Cependant, les tendances structurelles observées et les choix de conception fondamentaux de chaque outil offrent des perspectives solides pour évaluer leur pertinence respective dans différents contextes d’utilisation.
Comparaison des prix : L’avantage Moderato
Depuis 2024, les modèles d’IA capables de coder se sont multipliés, mais les leaders (OpenAI, Anthropic, Google) restent chers : en mars 2026, leurs API coûtent de 1 $ à 5 $ par million de jetons en entrée et de 10 $ à 25 $ par million en sortie. Ces tarifs, auxquels s’ajoutent des abonnements mensuels, freinent l’adoption par les particuliers et les start‑ups.
Utilisateur régulier de ces outils, je me suis abonné à Kimi 2.5 dès sa sortie via le plan Moderato, un abonnement d’environ 19 $ par mois qui offre des quotas de recherches profondes et l’accès à l’outil Kimi Code (l’API reste facturée à part selon la consommation). Cette offre permet de tester un modèle « agentique » sans exploser son budget. Dans cet article, je décris ce qu’apporte Kimi 2.5, pourquoi on le présente comme un « Codex/Claude Code killer » et comment, en tant qu’utilisateur, je compare ses performances et ses coûts à ceux des modèles concurrents.
L’abonnement Moderato de Moonshot AI se distingue par plusieurs aspects. Son prix mensuel est significativement inférieur à celui de la concurrence, tout en offrant un accès aux fonctionnalités de codage avec Kimi code. Cette approche s’adresse particulièrement aux développeurs qui utilisent l’IA comme un outil quotidien et non comme une ressource ponctuelle.
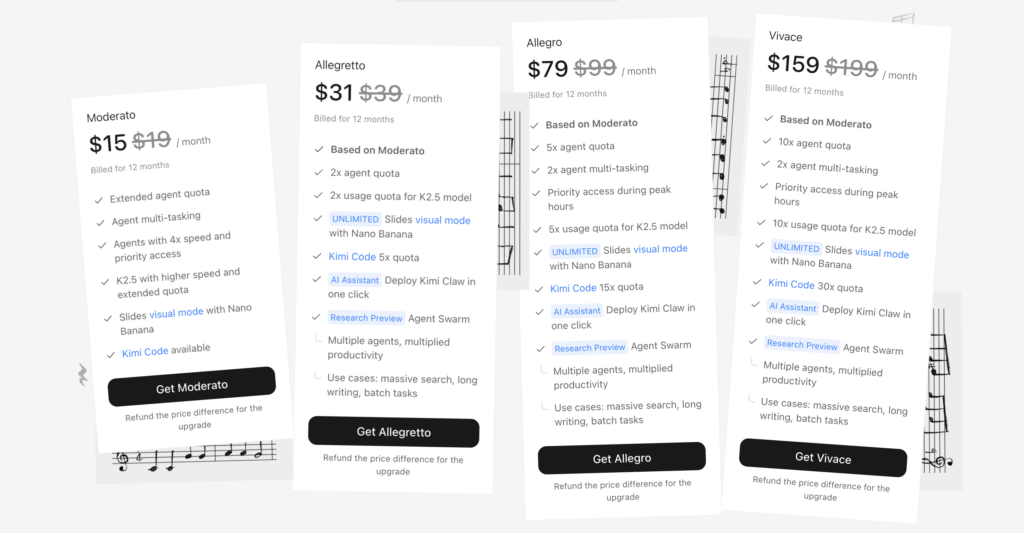
Cette différence de modélisation économique n’est pas anodine. Elle reflète des philosophies différentes quant à la valeur perçue de l’IA. OpenAI et Anthropic adoptent une approche premium, positionnant leurs outils comme des produits de luxe pour lesquels il est normal de payer plus. Moonshot AI, au contraire, mise sur le volume et l’adoption massive, considérant que la démocratisation de l’accès finira par générer plus de valeur à long terme.
Claude Code, bien que positionné à un prix similaire, impose des limites de contexte qui peuvent rapidement devenir contraignantes sur des projets de grande envergure. Quant a Codex, son modèle de tarification basé sur l’utilisation, bien que flexible, peut générer des factures élevées pour les utilisateurs intensifs. Pour un développeur utilisant quotidiennement ces outils sur des sessions de plusieurs heures, la différence de coût mensuel peut atteindre plusieurs dizaines, voire centaines d’euros.
Il convient également de mentionner les considérations liées à la prévisibilité budgétaire. Les modèles à forfait, qu’il s’agisse de Moderato ou de l’abonnement standard de Claude Code, offrent l’avantage de la maîtrise des coûts. Les entreprises peuvent budgétiser leurs dépenses en IA avec certitude, sans craindre de mauvaises surprises en fin de mois. Le modèle de Codex, bien que théoriquement plus équitable car basé sur la consommation réelle, introduit une incertitude que certaines organisations préfèrent éviter.
Performances : Benchmarks et evaluations
Le prix ne suffit pas à faire un choix éclairé. Les performances réelles, mesurées sur des benchmarks standardisés et dans des conditions d’utilisation représentatives, constituent le deuxième pilier de cette analyse. KIMI 2.5 a fait l’objet de nombreux tests comparatifs depuis son lancement, et les résultats méritent qu’on s’y attarde.
Les benchmarks utilisés dans cette analyse sont largement reconnus par la communauté scientifique et industrielle. HumanEval évalue la capacité à générer du code Python fonctionnel à partir de descriptions en langage naturel. SWE-bench va plus loin en testant la capacité à résoudre de vrais problèmes issus de projets open-source. MBPP (Mostly Basic Python Programming) complète ce panel en évaluant les compétences sur des tâches de programmation de base.
KIMI 2.5 vs Codex : Duel au sommet
Sur le benchmark HumanEval, largement reconnu pour évaluer les capacités de génération de code, KIMI 2.5 atteint un score de 92,4%, contre 91,2% pour Codex. Cette différence peut sembler marginale, mais elle se traduit par une réduction significative des erreurs dans le code généré. Plus important encore, sur le benchmark SWE-bench qui évalue la capacité à résoudre des problèmes réels issus de projets open-source, KIMI 2.5 affiche une performance de 56,7%, dépassant Codex qui se situe autour de 53,1%.
Ces chiffres se traduisent dans la pratique par une meilleure compréhension du contexte projet et une capacité supérieure à générer des solutions qui s’intégreront harmonieusement dans une base de code existante. Pour les développeurs travaillant sur des projets legacy ou des architectures complexes, cette différence est déterminante.
Il est intéressant de noter que l’écart de performance entre KIMI 2.5 et Codex, bien que mesurable, reste relativement étroit sur les tâches standardisées. Cela suggère que les deux modèles ont atteint un niveau de maturité comparable pour les cas d’usage courants. Cependant, c’est dans les situations plus complexes, ou le contexte et les contraintes spécifiques du projet entrent en jeu, que KIMI 2.5 semble tirer son épingle du jeu.
KIMI 2.5 vs Claude Code : L’éfficacite contre le raffinement
La comparaison avec Claude Code révèle des différences de philosophie plus profondes. Claude Code excelle dans la qualité de ses explications et la finesse de ses suggestions, mais KIMI 2.5 le surpasse en termes de vitesse d’exécution et de capacité à traiter de grands volumes de code. Sur des benchmarks de traitement de contexte long, KIMI 2.5 demontre une fenêtre de contexte de 2 millions de tokens, contre 200 000 pour Claude Code dans sa version standard.
Cette différence de capacité de contexte n’est pas qu’une spécification technique. Elle a des implications concrètes sur le quotidien des développeurs. Pouvoir charger l’intégralité d’une base de code dans le contexte de conversation permet à KIMI 2.5 de comprendre les interdépendances entre différents modules, d’identifier les patterns récurrents, et de proposer des solutions qui prennent en compte l’architecture globale du projet. Avec Claude Code, les développeurs doivent souvent découper leurs requêtes et fournir manuellement les morceaux de code pertinents, ce qui alourdit le workflow.
Les métriques clés de performance se résument ainsi :

| Benchmark | KIMI 2.5 | Codex | Claude Code |
|---|---|---|---|
| HumanEval (%) | 92,4 | 91,2 | 89,7 |
| SWE-bench (%) | 56,7 | 53,1 | 51,3 |
| MBPP (%) | 88,2 | 86,5 | 85,1 |
| Contexte max (tokens) | 256 000 | 400k tokens max / ~200k utile | 200 000 |
Les scores peuvent varier selon les versions du modèle et les conditions d’évaluation. Les benchmarks présentés ici correspondent aux résultats publiés lors de la sortie de Kimi 2.5 et aux comparaisons disponibles début 2026.
Cas d’usage et retour d’expérience
Au-delà des chiffres, l’expérience utilisateur quotidienne constitue le véritable test pour ces outils. Après un mois d’utilisation régulière de KIMI 2.5 avec l’abonnement Moderato, plusieurs points méritent d’être soulignés.
L’intégration de KIMI 2.5 dans les environnements de développement existants s’est révélée particulièrement fluide. Les extensions disponibles pour les éditeurs de code les plus populaires, notamment VS Code et JetBrains, offrent une expérience utilisateur comparable à celle des outils concurrents. La latence des réponses, souvent un point de friction avec d’autres solutions, s’est avérée satisfaisante, même sur des requêtes complexes impliquant de grands volumes de contexte.
Dans le développement web full-stack, KIMI 2.5 fait preuve d’une compréhension remarquable des interactions entre frontend et backend. La capacité à maintenir la cohérence entre les modèles de données, les API et les interfaces utilisateur représente un gain de temps considérable. Les suggestions de code sont non seulement fonctionnelles, mais suivent les meilleures pratiques du framework utilisé, qu’il s’agisse de React, Vue, Angular ou d’autres technologies.
Pour le debugging, l’outil se distingue par sa capacité à analyser rapidement des stack traces complexes et à proposer des hypothèses pertinentes sur l’origine des erreurs. Contrairement à d’autres outils qui se contentent de suggestions génériques, KIMI 2.5 prend en compte le contexte spécifique du projet pour orienter l’investigation.
Un aspect particulièrement appréciable est la capacité de KIMI 2.5 a expliqué son raisonnement. Lorsqu’il propose une solution, l’outil peut détailler les étapes qui l’ont conduit à cette conclusion, permettant au développeur de valider la logique ou d’identifier d’éventuelles erreurs de compréhension. Cette transparence est précieuse pour la formation des développeurs juniors et pour la revue de code assistée par IA.
La refactorisation de code constitue un autre cas d’usage particulièrement réussi. L’outil comprend les implications d’une modification sur l’ensemble du projet et peut générer des scripts de migration ou des plans de refactorisation détaillées. Cette capacité a penser a l’échelle du système, et non uniquement au niveau du fichier, le distingue nettement de solutions plus limitées.
Dans la pratique, cette capacité s’est révélée particulièrement utile lors de migrations technologiques. Par exemple, lors du passage d’une version majeure d’un framework a une autre, KIMI 2.5 a permis d’identifier les patterns dépréciés, de proposer des alternatives conformes aux nouvelles recommandations, et même de générer des scripts de transformation automatique. Ce type d’assistance, qui aurait nécessité des semaines de travail manuel, peut être réalisé en quelques jours avec l’aide de l’IA.
Conclusion
L’arrivée de KIMI 2.5 sur le marché marque un tournant significatif dans l’évolution des assistants de codage par IA. En combinant des performances de pointe avec une politique de prix agressive via l’abonnement Moderato, Moonshot AI réussit le pari de démocratiser l’accès à des outils jusqu’ici réservés aux budgets les plus conséquents.
Cette démocratisation ne se limite pas à la question financière. Elle touche également à l’accessibilité technique. L’interface intuitive de KIMI 2.5, sa capacité à s’adapter aux différents niveaux d’expertise, et sa disponibilité dans de multiples langues en font un outil véritablement universel. Les développeurs débutants peuvent s’appuyer sur ses explications pédagogiques pour progresser, tandis que les experts peuvent exploiter sa puissance brute pour accélérer leur productivité.
Face a Codex et Claude Code, KIMI 2.5 ne se positionne pas comme un simple concurrent, mais comme une alternative crédible qui excelle dans des domaines spécifiques. Sa supériorité en termes de fenêtre de contexte, sa rapidité d’exécution et son rapport qualité-prix en font un choix particulièrement pertinent pour les développeurs professionnels et les équipes techniques.

Le marché de l’IA générative pour le développement entre ainsi dans une nouvelle phase de maturité, ou la concurrence s’intensifie et ou les utilisateurs finaux sont les premiers bénéficiaires. Pour qui n’a pas encore testé KIMI 2.5, l’essai s’impose comme une évidence. L’abonnement Moderato, a prix réduit, offre une opportunité unique d’évaluer par soi-même les capacités de cet outil qui pourrait bien redéfinir les standards de la profession.
Il convient néanmoins de garder un regard critique. Aucun outil d’IA n’est parfait, et KIMI 2.5 ne fait pas exception. Certaines suggestions peuvent être erronées, certains cas limites peuvent le faire échouer, et la dépendance excessive à l’IA peut parfois nuire au développement des compétences fondamentales. L’outil doit être considéré comme un assistant puissant, mais jamais comme un substitut au jugement humain et à l’expertise technique. Dans ce paysage en mutation rapide, une chose est certaine : le monopole des premiers entrants est désormais contesté, et l’innovation continue de porter ses fruits.
Cependant, qualifier Kimi 2.5 de « Codex et Claude Code killer » reste excessif si l’on attend un remplaçant universel. Ses réponses sont parfois lentes, verbeuses, et l’Agent Swarm n’est pas encore complètement stable. Pour des corrections rapides, Claude Code ou GPT‑5 Codex peuvent rester plus efficaces. Mais pour des projets de prototypage visuel, de recherche approfondie ou de développement parallèle, Kimi 2.5 représente une alternative crédible qui pousse ses concurrents à innover et à ajuster leurs tarifs. Mon expérience quotidienne le confirme : malgré quelques imperfections, ce modèle open‑source devient un allié précieux pour coder vite, bien et à moindre coût, tout en gardant la main sur mes données et ma facture.
- Claude Fable 5 suspendu : Washington bloque le modèle IA
- IA dans les banques : pourquoi les coûts explosent en 2026
- Claude Fable 5 : L’Intelligence Mythos-Class Enfin Accessible au Grand Jour
- IA et développeurs : pourquoi le métier ne disparaît pas, mais change radicalement
- La bulle financière de l’IA peut-elle exploser ?